ダブルケアのページ一覧


MH:W | GPU Particle - モンスターハンター:ワールドにおけるGPU Particleの実装の#P85


配信者 vs 視聴者多数!ライブ動画配信プラットフォームを活用した、非対称マルチプレイを実現するシステムの構築の#P25

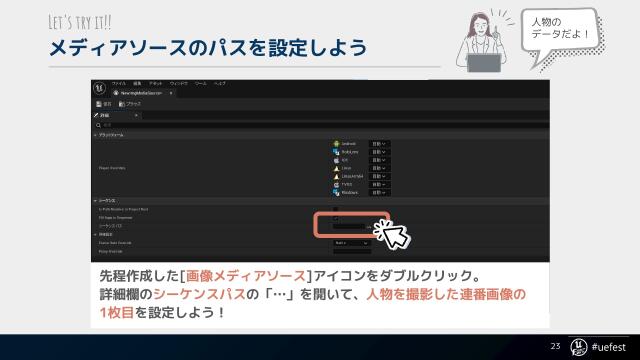
誰でも始められる!知識ゼロから自宅で本格【実写+3DCGミュージックビデオ】の作り方【UNREAL FEST WEST ’22】の#P23
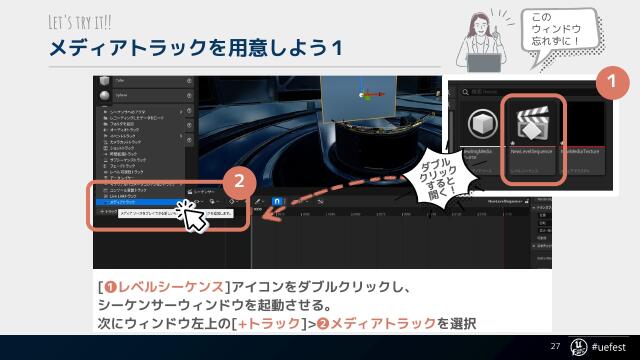
誰でも始められる!知識ゼロから自宅で本格【実写+3DCGミュージックビデオ】の作り方【UNREAL FEST WEST ’22】の#P27
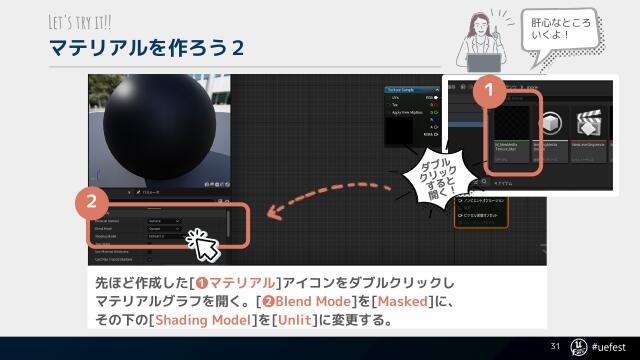
誰でも始められる!知識ゼロから自宅で本格【実写+3DCGミュージックビデオ】の作り方【UNREAL FEST WEST ’22】の#P31

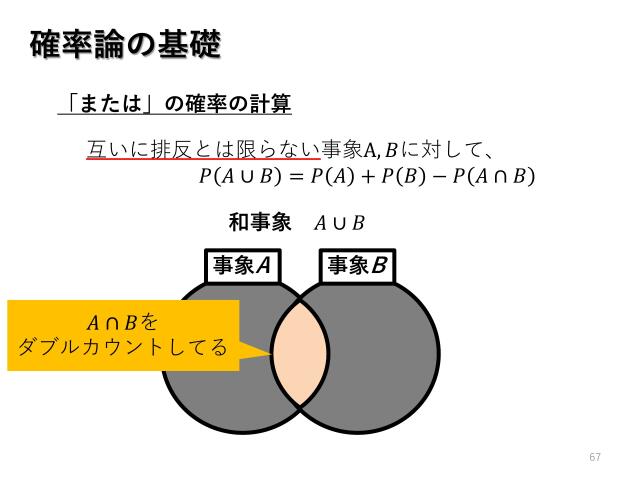
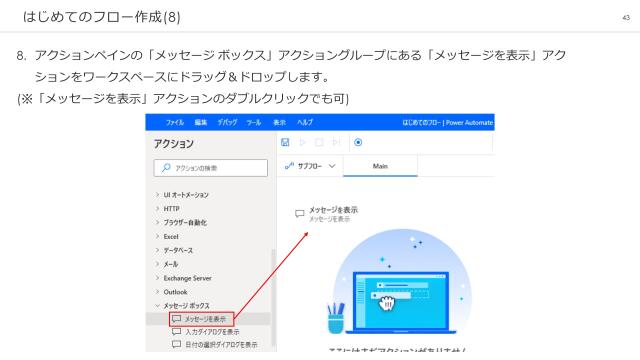


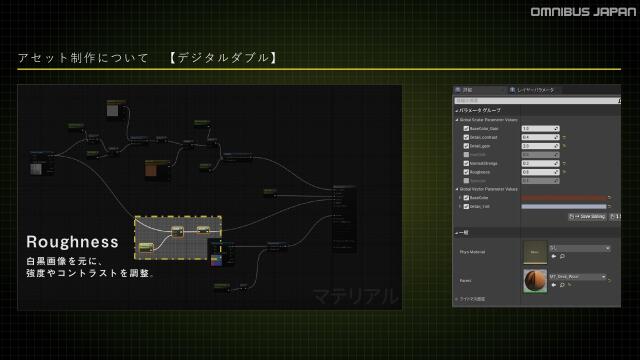
プリレンダーアーティストが挑むバーチャルプロダクション制作【Virtual Production Deep Dive 2023】の#P25