Azure Open AI の RAG で C# のサンプルを作ってみた。
17.4K Views
February 18, 24
スライド概要
Azure Open AI で C# のRAGのサンプルを作成しました。Pythonのサンプルが多い中、C# 用のサンプルはあまりないので作成してみました。ブログの記事を関数アプリで10分ごとにクロールし、html として Blob に保存することで、AI Search にベクトルを含むドキュメントを登録し、チャットプレイグラウンドにて独自ナレッジの連携を試せるサンプルを作成しました。
SIerの人。Xamarin.iOS が好き。Azure と戯れるのが仕事。Visual Studio for Mac が Win版と同等になる日を切望。Microsoft MVP Developer Technologies 2017-
関連スライド




各ページのテキスト
Azure Open AI で C# の RAG サンプルを 作ってみた。 Tomohiro Suzuki @hiro128_777 2024-2-21
自己紹介 鈴木友宏 Azure Open AI、Azure、 M365、Power Platform、.NET などの Microsoft 製品を用 いたシステムの構築をしています。 このスライドの URL C# Tokyo 運営メンバー Twitter:@hiro128_777 blog:https://hiro128.hatenablog.jp/ 2
ご注意 • Azure Open AI 関連の SDK は Preview も多く実際に頻繁に変更されており、NuGet パッケージのバージョンが異なると動作しない場合があります。 • SKEXP0055 (Experimental 属性)が付与されている機能も利用していますので、今後 変更の可能性があることご了承下さい。 • よって、サンプルをデプロイして検証いただく場合、 NuGet パッケージのバージョンを当サンプ ルで利用しているバージョンに厳密に合わせるか、変更点を確認してソースコードを変更して 下さい。 • この資料を参考にサンプルアプリをデプロイすると \20,000/月程度の課金が発生します。 課金に関しては自己責任となり、筆者は一切責任を負いません。 3
動機 Azure Open AI の RAG のサンプ ルって大体 Python だな~。 C# が大好きだし、C# でやってみた いな~。 とりあえず、参考になりそうなサンプ ルを探してみよう。 4
探してみたら、素晴らしいサンプルがありました!! https://github.com/microsoft/sample-app-aoai-chatGPT 上記サンプルがあまりにも神すぎて、このサンプルだけで、Azure Open AI の Add your data と組み合わせて独自ナレッジの連携を試せるのですが、逆に全自動すぎて何が行われ ているか理解できません(笑)。そこで、知見を増やすためにこのサンプルをカスタマイズして 何か作ってみて理解を深めることにしました 5
カスタマイズ方針 • 言語は C# にする。(Python のサンプルが多いので C# のサンプルを作成したい) • ソースデータはファイルとしていつでも開けるように Blob にファイルとして保存する。 • 各々の処理は関数アプリにして自動化する。 • あまり複雑にしないで、シンプルに必要な要素を学べるサンプルにしたい。 • 自分にとって役に立ち、運用できるサンプルにしたい。 6
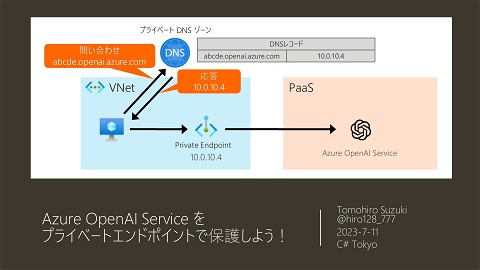
検討した、システム構成と処理フロー はてなブログの記事を関数アプリで10分ごとにクロールし、Blob に html として保存する。 Blob にアイテムが追加されると、Event Grid の Blob Trigger の関数アプリで AI Search にベクトルを含むドキュメントを登録する。 PC はてなブログ Functions (C#) WebPageCrawler ❶ Blob コンテナ Event Grid システムトピック Functions (C#) AI Search Azure AI Studio チャット プレイグラウンド (動作確認用) IndexCreator RA-GRS / StorageV2 NEW 記事投稿 Timer Triggerで 記事をクロールして HTML ❷新規記事があれば Blob 項目が作成されると Blob Created イベントが 発行される HTML を取得し Blob に保存 HTML 自分が利用できるようにはてなブログの記事をソース データにしていますが、ソースデータはその他ブログでも 社内のドキュメントでもなんでもかまいません。 ❸ JSON HTML ❹ チャンク(分割)して、 ベクトルを含むドキュ メントを登録 Index Index 追加した ドキュメントに 基づく回答 Index 7
ソースコードと各プロジェクトの解説 本資料のソースコードは以下のリポジトリを参照ください。 https://github.com/TomohiroSuzuki128/aoai-myblog/ プロジェクト名 説明 AIClient Open AI, AI Search などのクライアントの Facade。 AzureAISearchIndexInitializer AI Search のインデックスを(既存インデックスが存在すればいったん削除し)作成するコンソールアプリ。 IndexCreator Blob 項目の追加、更新をトリガーにインデックスを作成・更新する関数アプリ。 TextChunkerSample TextChunker の挙動を確認するためのサンプルアプリ。 WebPageCrawler はてなブログの記事をクロールして Blob にアーカイブする関数アプリ。 8
調査してみて気づいた留意点 ① C# では Python と比べて日本語の言語処理にやチャンク(テキスト分割)に関して圧倒的にライブラリが 少ないが、html ファイルのクレンジングやテキストをチャンクする際のトークンカウンターをどうするか。 ② ソースのブログ記事が更新されたとき、インデックス上の当該ドキュメントを削除する判断基準となるはてなブ ログ記事の更新日時の管理はどうするか。 ③ インデックスはキー属性が付与された値でしか削除できないので、ソースデータ更新時にどうやって削除するか。 9
留意点①:C# によるテキストのクレンジング・チャンク 日本語の言語処理やチャンク(テキスト分割)に関して C# は圧倒的にライブラリが少ない点をどう解決するか A) 現状提供されているSDK/ライブラリでどうにかする 今回はこちらを使用 • Python にあるようなリッチなライブラリは現状ない • markdown とプレーンテキストならプレビューではあるが、 Microsoft.SemanticKernel.TextChunker が 対応している B) Python の処理を C# に移植する • Python の標準ライブラリは言語処理関連が充実しているが、必要な処理すべてを C# に移植するのは 量的に困難 • 現状提供されているライブラリがない機能を移植する 一部機能は Python を移植 10
留意点①ーA: SemanticKernel.TextChunker を使う SemanticKernel.TextChunker の公式ドキュメントは以下を参照ください。 https://learn.microsoft.com/enus/dotnet/api/microsoft.semantickernel.text.textchunker?view=semantic-kernel-dotnet 提供メソッドは以下の4種類(現状 markdown とプレーンテキストのみ対応) ① SplitMarkDownLines(String, Int32, TextChunker.TokenCounter) markdownテキストを行に分割します。 ② SplitMarkdownParagraphs(List<String>, Int32, Int32, String, TextChunker.TokenCounter) markdownテキストを段落に分割します。 ③ SplitPlainTextLines(String, Int32, TextChunker.TokenCounter) プレーンテキストを行に分割します。 ④ SplitPlainTextParagraphs(List<String>, Int32, Int32, String, TextChunker.TokenCounter) プレーンテキストを段落に分割します。 html からプレーンテキストを抽出(クレンジング)し、③、④のメソッドでチャンクする方針とします。 11
- https://learn.microsoft.com/en-us/dotnet/api/microsoft.semantickernel.text.textchunker?view=semantic-kernel-dotnet
- https://learn.microsoft.com/en-us/dotnet/api/microsoft.semantickernel.text.textchunker.splitmarkdownlines?view=semantic-kernel-dotnet
- https://learn.microsoft.com/en-us/dotnet/api/microsoft.semantickernel.text.textchunker.splitmarkdownparagraphs?view=semantic-kernel-dotnet
- https://learn.microsoft.com/en-us/dotnet/api/microsoft.semantickernel.text.textchunker.splitplaintextlines?view=semantic-kernel-dotnet
- https://learn.microsoft.com/en-us/dotnet/api/microsoft.semantickernel.text.textchunker.splitplaintextparagraphs?view=semantic-kernel-dotnet
留意点①ーA:SplitPlainTextParagraphs メソッドの留意点 パラメータ名 型 説明 lines List<String> テキストの行。 maxTokensPerParagraph Int32 段落ごとのトークンの最大数。 overlapTokens Int32 段落間で重なるトークンの数。 chunkHeader String 個々のチャンクの前に追加されるテキスト。 tokenCounter delegate int TokenCounter(string input) 文字列内のトークンをカウントする関数。指定しない場合は、デフォルトのカウンターが 使用される。 正しくトークンをカウントする必要があるので、ポイン トになるのが、TokenCounter ですが、この実体は ソースコードを確認すると、string をパラメータとし、 int を返すデリゲートになっています。 よって、自分がデプロイした Enbedding モデルに適 合した TokenCounter のデリゲートを渡すようにし ます。 12
留意点①ーA: TokenCounter の実装 作成したソースコードの詳細は以下を参照ください。 https://github.com/TomohiroSuzuki128/aoai-myblog/blob/main/IndexCreator/TokenEstimator.cs トークンカウンターは、ベクトルインデックス作成時の embedding モデルに合わせる必要があります。 Python では https://github.com/openai/tiktoken がスタンダードです。 C# では tiktoken をもとにした C# 実装の Microsoft.DeepDev.TokenizerLib https://github.com/microsoft/Tokenizer を利用します。 13
留意点①ーB:html ファイルのクレンジング 作成したソースコードの詳細は以下を参照ください。 https://github.com/TomohiroSuzuki128/aoai-myblog/blob/main/IndexCreator/Cleanser.cs 参考にした以下の Python サンプルの実装を参考に最低限度必要な機能(parser)のみを C# に移植しました。 (本当に最低限度なので、改良の余地は多いにあります。) https://github.com/microsoft/sample-app-aoaichatGPT/blob/31dbce2b19ffcf2ecb5b05847ee44df9b6d0c344/scripts/data_utils.py#L241 具体的には、インデックスには title フィールドと、content フィールドが必要なので、タイトルと記事の文章を抽 出し、なるべくゴミを除去する機能を実装しています。 14
留意点②:Blob コンテナでのソースデータの更新日時の管理 ストレージアカウントのSKU Blob 側の最終変更日は、コンテナにファイルがアップロードされた日時なので、 コンテナの項目のメタデータにソース記事の url とはてなブログの更新日時を記録しておきます 日時が異なっている 15
留意点②:Blob コンテナでのソースデータの更新日時の管理 前ページのとおりはてなブログでの更新日時が必要なため、Blob にアップロードする際に、 はてなブログの当該記事の url と 最 終更新日時をメタデータとして付与します。 作成したソースコードの詳細は以下を参照ください。 https://github.com/TomohiroSuzuki128/aoaimyblog/blob/dfccf7166978168b0d5a103b317cdc319dc3ba3c/WebPageCrawler/HatenaCrawler.cs#L164 16
参考:Blob のイベントサブスクリプションを作成する 17
Tips:Blob のイベントサブスクリプション作成中にエラーが出たら 利用中の Azure サブスクリプションで Event Grid を使用したことがない場合、以下のようなエラーが発生する可能性があります。 発生した場合は、Azure CLI で以下のプロバイダーを登録するコマンドを実行し、Event Grid リソースプロバイダーを登録します。 az provider register --namespace Microsoft.EventGrid 登録完了まで少し時間がかかることがあるので、 状態を確認するには、次のコマンドを実行します az provider show --namespace Microsoft.EventGrid --query "registrationState" 18
留意点③: AI Search の検索インデックス作成 AI Search のインデックスを一括で作成するコンソールアプリを準備しています。 https://github.com/TomohiroSuzuki128/aoai-myblog/tree/main/AzureAISearchIndexInitializer フィールド定義の詳細は以下の公式ドキュメントを参照ください。 https://learn.microsoft.com/ja-jp/rest/api/searchservice/create-index#-field-definitions検索インデックス=テーブル ドキュメント=テーブルにおける行 というイメージでほぼOKです。 key 日本語にする 19
留意点③: AI Search のインデックス作成 セマンティック構成 ベクタープロファイル 20
留意点③:ドキュメントの削除 作成したソースコードの詳細は以下を参照ください。 https://github.com/TomohiroSuzuki128/aoaimyblog/blob/f02454f2dbd2ed44d215ce0817fc93d575672acf/IndexCreator/IndexCreator.cs#L113 ドキュメントは、key 属性が設定されたフィールドの値指定でしか削除できないので、特定の記事のドキュメントを url フィールドで検索してドキュメントを取得し、 id フィールドの値を指定して削除します。 key 属性 21
留意点④:「データの追加」の設定 22
留意点④:「データの追加」の設定 23
留意点④:「データの追加」の設定 24
デフォルトのチャットアプリをデプロイしてみる 25
デフォルトのチャットアプリをデプロイしてみる 自分で登録したドキュメントの 内容に関する質問を投げて 回答が想定通りに出ればOK 26
さらなるカスタマイズのアイデア • チャットアプリを自由にカスタマイズしたい Azure OpenAI Studio からデプロイできるデフォルトのチャットアプリではなく https://github.com/microsoft/sample-app-aoai-chatGPT/tree/main/frontend をカスタマイズしてデプロイします。 その他、 • フロントエンドを Web アプリではなく Teams の Bot にする。 • ポータルサイトに組み込む なども可能です。 27
その他のTips • Functions のローカルデバッグはいろいろと面倒です。 • Event Grid からのイベント受信のローカルデバッグをどうするか(ダミーイベントの json を Postman で localhost に送信 or ngrok 等で実際のイベントを開発環境に送信) • 関数でエラー発生時のイベント受信のリトライおよび関数の同時実行数を抑制しないと、Functions ランタ イムによってアプリのプロセスが複数走り、まともにデバッグできませんが、設定変更のやり方がわかりにくい です。(local.setting.json に設定値を記載。Azure 上の host.json と違い階層を「アンダースコア x 2(__) で表現する」) • “AzureFunctionsJobHost__extensions__blobs__maxDegreeOfParallelism”: “1”, • "AzureFunctionsJobHost__extensions__blobs__poisonBlobThreshold": "1“ 28
ご清聴ありがとうございました 29