BigQueryにおけるページURL正規化と最新タイトル取得の完全解剖
>100 Views
May 16, 26
スライド概要

関連スライド




各ページのテキスト
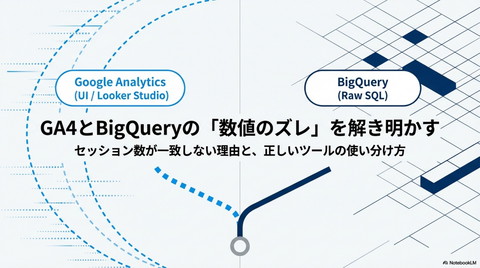
GA4 Data Extraction Pipeline URLクレンジングと最新ページタイトルの取得:BigQuery SQLの段階的解剖とアーキテクチャ解説
Query Minimap SELECT clean_url, ARRAY_AGG( page_title IGNORE NULLS ORDER BY event_timestamp DESC LIMIT 1 )[SAFE_OFFSET(0)] AS page_title FROM ( SELECT event_timestamp, REGEXP_REPLACE( (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'), r'?. *$', '') AS clean_url, (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_title') AS page_title FROM <project>.<dataset>.events_* WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY)) AND event_name = 'page_view' ) WHERE clean_url IS NOT NULL GROUP BY clean_url ORDER BY clean_url The Blueprint (全体像とビジネス要件) 目的: 過去30日間のページビューデータから、クエリ パラメータを排除した「クリーンなURL」を一意に抽 出し、それぞれのURLで「最後に計測された(最新 の)ページタイトル」を取得する。 入力: GA4 Raw Data SQL Pipeline 出力: Cleaned URL & Latest Title 課題: GA4データのネスト構造 (event_params)、 URLのノイズ (パラメータによる分散)、および 最新状態を決定するための時間軸集計。
Query Minimap SELECT clean_url, ARRAY_AGG( page_title IGNORE NULLS ORDER BY event_timestamp DESC LIMIT 1 )[SAFE_OFFSET(0)] AS page_title FROM ( SELECT event_timestamp, REGEXP_REPLACE( (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'), r'?. *$', '') AS clean_url, (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_title') AS page_title FROM <project>.<dataset>.events_* WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY)) AND event_name = 'page_view' ) WHERE clean_url IS NOT NULL GROUP BY clean_url ORDER BY clean_url Pipeline Architecture: 実行パイプラインの解体 SQLの記述順ではなく、データベースエンジンの実行順序に従い、 内側の抽出フェーズから外側の集約フェーズへとステップ・バイ・ ステップで解体する。 Phase 2: Main Query (Outer) ノイズ除去 URLごとの グループ化 時間軸に基づく 最新タイトルの抽出 Phase 1: Subquery (Inner) 読み取り範囲の 限定 イベントの 絞り込み ネスト解除と URLクレンジング
Query Minimap SELECT clean_url, ARRAY_AGG( page_title IGNORE NULLS ORDER BY event_timestamp DESC LIMIT 1 )[SAFE_OFFSET(0)] AS page_title FROM ( SELECT event_timestamp, REGEXP_REPLACE( (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'), r'?. *$', '') AS clean_url, (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_title') AS page_title FROM <project>.<dataset>.events_* WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY)) AND event_name = 'page_view' ) WHERE clean_url IS NOT NULL GROUP BY clean_url ORDER BY clean_url Phase 1: Data Source & Partitioning Data Source: ワイルドカード テーブル (events_*) を対象 とする。 Scan Focus: events_* + _TABLE_SUFFIX 過去30日のテーブル (events_YYYYMMDD) Optimization: _TABLE_SUF FIX を使用してスキャン範 囲を過去30日分に限定。 全期間スキャンを回避し、ク エリコストと実行時間を劇的 に削減。
Query Minimap SELECT clean_url, ARRAY_AGG( page_title IGNORE NULLS ORDER BY event_timestamp DESC LIMIT 1 )[SAFE_OFFSET(0)] AS page_title FROM ( SELECT event_timestamp, REGEXP_REPLACE( (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'), r'?. *$', '') AS clean_url, (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_title') AS page_title FROM <project>.<dataset>.events_* WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY)) AND event_name = 'page_view' ) WHERE clean_url IS NOT NULL GROUP BY clean_url ORDER BY clean_url Phase 1: Event Filtering Input click session_start scroll page_view event_name = 'page_view' Output page_view Event Filtering: 膨大なGA4 イベントデータから 「ページビュー」イベント のレコードのレコードの みを厳密に抽出。 State Change: 過去30日のすべての page_view イベントの生 データが、後続の抽出・整 形プロセスの入力となる。
Query Minimap
SELECT
clean_url,
ARRAY_AGG( page_title IGNORE NULLS
ORDER BY event_timestamp DESC LIMIT 1
)[SAFE_OFFSET(0)] AS page_title
FROM (
SELECT
event_timestamp,
REGEXP_REPLACE(
(SELECT value.string_value
FROM UNNEST(event_params)
WHERE key = 'page_location'),
r'?. *$', '')
AS clean_url,
(SELECT value.string_value
FROM UNNEST(event_params)
WHERE key = 'page_title')
AS page_title
FROM <project>.<dataset>.events_*
WHERE _TABLE_SUFFIX BETWEEN
FORMAT_DATE('%Y%m%d',
DATE_SUB(CURRENT_DATE('Asia/Tokyo'),
INTERVAL 30 DAY))
AND FORMAT_DATE('%Y%m%d',
DATE_SUB(CURRENT_DATE('Asia/Tokyo'),
INTERVAL 1 DAY))
AND event_name = 'page_view'
)
WHERE clean_url IS NOT NULL
GROUP BY clean_url
ORDER BY clean_url
Phase 1: Parameter Extraction (ネスト解除)
Data Shape Transformation
Before
event_params (JSON Array)
{key: 'page_location', value: '...
{key: 'page_title', , value: '...}
{key: 'page_title', value: '...'}
{key: 'session_id', value: '...'}
UNNEST()
+
Scalar Subquery
After
page_location
page_title
url_string
title_string
Unnesting Arrays: GA4特有のネストされた配列データ `event_params`
を `UNNEST` で行に展開。
Scalar Subquery: スカラーサブクエリを用いることで、同一イベント
行内で対象のキーだけをピンポイントで引き抜き、フラットな独立カ
ラムとして生成。Query Minimap SELECT clean_url, ARRAY_AGG( page_title IGNORE NULLS ORDER BY event_timestamp DESC LIMIT 1 )[SAFE_OFFSET(0)] AS page_title FROM ( SELECT event_timestamp, REGEXP_REPLACE( (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'), r'?. *$', '') AS clean_url, (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_title') AS page_title FROM <project>.<dataset>.events_* WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY)) AND event_name = 'page_view' ) WHERE clean_url IS NOT NULL GROUP BY clean_url ORDER BY clean_url Phase 1: URL Cleansing String Manipulation 1 Before: https://example.com/item?utm_source=google&gclid=123 2 REGEXP_REPLACE (r'?. *$') ?以降の文字列すべてをキャプチャし、空文字 '' に置換 3 After: https://example.com/item Explanation Text Panel ● URL Cleansing: 不要なクエリパラメータ (マーケティングトラッキング等) を正規表現で一 掃。 ● Logic: 同一ページでありながらパラメータ違いで分散していたURLノイズを排除し、単一の clean_url として集約可能な状態へ整える。
Query Minimap
SELECT
clean_url,
ARRAY_AGG( page_title IGNORE NULLS
ORDER BY event_timestamp DESC LIMIT 1
)[SAFE_OFFSET(0)] AS page_title
FROM (
SELECT
event_timestamp,
REGEXP_REPLACE(
(SELECT value.string_value
FROM UNNEST(event_params)
WHERE key = 'page_location'),
r'?. *$', '')
AS clean_url,
(SELECT value.string_value
FROM UNNEST(event_params)
WHERE key = 'page_title')
AS page_title
FROM <project>.<dataset>.events_*
WHERE _TABLE_SUFFIX BETWEEN
FORMAT_DATE('%Y%m%d',
DATE_SUB(CURRENT_DATE('Asia/Tokyo'),
INTERVAL 30 DAY))
AND FORMAT_DATE('%Y%m%d',
DATE_SUB(CURRENT_DATE('Asia/Tokyo'),
INTERVAL 1 DAY))
AND event_name = 'page_view'
)
WHERE clean_url IS NOT NULL
GROUP BY clean_url
ORDER BY clean_url
Phase 1 Checkpoint: 内部処理の完了状態
event_timestamp
clean_url
page_title
1698710400
/product-a
Product A Details
1698710405
/product-a
Product A - Sale
1698710410
/about
About Us
1698710412
null
null
Explanation Text Panel
● Phase 1 Output: 内部サブクエリの実行が完了。生データから
必要な情報が抽出・フラット化・整形され、3カラムの一時テー
ブルが生成された状態。
● Next Step: このインメモリテーブルを入力ソースとし、外部メ
インクエリ (Phase 2) での高度な集約・フィルタリング処理へ
と移行する。Query Minimap
SELECT
clean_url,
ARRAY_AGG( page_title IGNORE NULLS
ORDER BY event_timestamp DESC LIMIT 1
)[SAFE_OFFSET(0)] AS page_title
FROM (
SELECT
event_timestamp,
REGEXP_REPLACE(
(SELECT value.string_value
FROM UNNEST(event_params)
WHERE key = 'page_location'),
r'?. *$', '')
AS clean_url,
(SELECT value.string_value
FROM UNNEST(event_params)
WHERE key = 'page_title')
AS page_title
FROM <project>.<dataset>.events_*
WHERE _TABLE_SUFFIX BETWEEN
FORMAT_DATE('%Y%m%d',
DATE_SUB(CURRENT_DATE('Asia/Tokyo'),
INTERVAL 30 DAY))
AND FORMAT_DATE('%Y%m%d',
DATE_SUB(CURRENT_DATE('Asia/Tokyo'),
INTERVAL 1 DAY))
AND event_name = 'page_view'
)
WHERE clean_url IS NOT NULL
GROUP BY clean_url
ORDER BY clean_url
Phase 2: Null Filtering (ノイズ除去)
event_timestamp
clean_url
page_title
1698710400
/product-a
Product A Details
1698710405
/product-a
Product A - Sale
1698710410
/about
About Us
1698710412
null
null
Explanation Text Panel
● Null Filtering: 外部クエリの最初のステップ。
● Data Quality: URLが存在しない不正なレコードや抽出失
敗したノイズを、後続のグループ化 (GROUP BY) の直前
に排除し、データ品質を担保する。Query Minimap
SELECT
clean_url,
ARRAY_AGG( page_title IGNORE NULLS
ORDER BY event_timestamp DESC LIMIT 1
)[SAFE_OFFSET(0)] AS page_title
FROM (
SELECT
event_timestamp,
REGEXP_REPLACE(
(SELECT value.string_value
FROM UNNEST(event_params)
WHERE key = 'page_location'),
r'?. *$', '')
AS clean_url,
(SELECT value.string_value
FROM UNNEST(event_params)
WHERE key = 'page_title')
AS page_title
FROM <project>.<dataset>.events_*
WHERE _TABLE_SUFFIX BETWEEN
FORMAT_DATE('%Y%m%d',
DATE_SUB(CURRENT_DATE('Asia/Tokyo'),
INTERVAL 30 DAY))
AND FORMAT_DATE('%Y%m%d',
DATE_SUB(CURRENT_DATE('Asia/Tokyo'),
INTERVAL 1 DAY))
AND event_name = 'page_view'
)
WHERE clean_url IS NOT NULL
GROUP BY clean_url
ORDER BY clean_url
Phase 2: Grouping & Ordering
[Group Key: /product-a]
t=1698710400: Product A Details
t=1698710405: Product A - Sale
[Group Key: /about]
t=1698710410: About Us
Explanation Text Panel
● Grouping Mechanism: clean_url を一意のキーとしてデータを集約。
● The Challenge: URLは一意になったが、グループ内には複数の異なるページタ
イトル (タイトル変更履歴やノイズ等) が混在している。ここから「正しい1つのタ
イトル」をどう決定するかが次の課題。SELECT clean_url, ARRAY_AGG(page_title IGNORE NULLS ORDER BY event_timestamp DESC LIMIT 1)[SAFE_OFFSET(0)] AS page_title FROM (SELECT event_timestamp, REGEXP_REPLACE( (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'), r'\\?. *$', '') AS clean_url, (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_title') AS page_title FROM <project>.<dataset>.events_* WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY)) AND event_name = 'page_view' ) WHERE clean_url IS NOT NULL GROUP BY clean_url ORDER BY clean_url Logic Comparison: 集計ロジックの選択基準 なぜ最新タイトルの取得に複雑な配列操作が必要なのか? 手法 A: MAX(page_title) 手法 B: サブクエリJOIN 手法 C: ARRAY_AGG (本実装) clean_url サブクエリ ARRAY_AGG 挙動: 文字列のアルファベット 順の最大値を返す。 挙動: 最新タイムスタンプを 別クエリで特定し結合する。 挙動: 要素を配列化し、時間 軸でソートして先頭を取得。 結果: ❌ 時間軸を無視し、 「Z」から始まる古いタイト ル等が誤判定される。 結果: ⚠️ コードが冗長化し、 スキャン量と処理コストが 増大する。 結果: ✅ 1スキャンで時間軸に 基づいた正確な最新値を抽出 可能。ベストプラクティス。 単純な集計関数では満たせないビジネス要件 (時系列の最新値取得) を、パフ ォーマンスを犠牲にせず解決するための高度なアプローチ。
Query Minimap SELECT clean_url, ARRAY_AGG( page_title IGNORE NULLS ORDER BY event_timestamp DESC LIMIT 1 )[SAFE_OFFSET(0)] AS page_title FROM ( SELECT event_timestamp, REGEXP_REPLACE( (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'), r'?. *$', '') AS clean_url, (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_title') AS page_title FROM <project>.<dataset>.events_* WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY)) AND event_name = 'page_view' ) WHERE clean_url IS NOT NULL GROUP BY clean_url ORDER BY clean_url Phase 2: Advanced Aggregation (核心部) 5つの独立した機能が1行のコード内で連鎖し、「最も新しい有効なタイト ル」を安全かつ効率的に抽出する完璧な機構。 1. 配列化 (ARRAY_AGG) ARRAY_AGG グループ内の タイトル群を リスト化。 2. NULL除外 (IGNORE NULLS) IGNORE NULLS 空のタイトル を配列から弾 く。 3. 時間降順 (ORDER BY DESC) ORDER BY event_ timestamp DESC タイムスタンプ 降順でソート (最新が先頭)。 4. メモリ節約 (LIMIT 1) LIMIT 1 配列の要素を 先頭1つだけ に絞り込み。 5. 安全抽出 ([SAFE_OFFS ET(0)]) [SAFE_OFFS ET(0)] 0番目(先頭) 要素をスカラー 値として抽出 (エラー回避)。
Query Minimap SELECT clean_url, ARRAY_AGG( page_title IGNORE NULLS ORDER BY event_timestamp DESC LIMIT 1 )[SAFE_OFFSET(0)] AS page_title FROM ( SELECT event_timestamp, REGEXP_REPLACE( (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'), r'?. *$', '') AS clean_url, (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_title') AS page_title FROM <project>.<dataset>.events_* WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY)) AND event_name = 'page_view' ) WHERE clean_url IS NOT NULL GROUP BY clean_url ORDER BY clean_url Final Synthesis: The Complete Data Pipeline Raw Events (events_*) Phase 1 Filters: 30 days & page_view Transforms: Unnesting & Regex Cleansing Phase 2 Grouping: By clean_url Aggregation: Array_Agg Pipeline Final Output: clean_url page_title Final Synthesis: 複雑なSQLも、データの「絞り込み」「整形」「集約」という明確 な役割を持ったパイプラインの集合体である。 Takeaway: BigQueryにおけるスキャン最適化と、高度な配列集計 (ARRAY_AGG) を両立させた、堅牢なデータモデリングの実践例。