GPT解説 ~汎用大規模言語モデルの起点~
22.3K Views
March 31, 23
スライド概要
GPTのモデル構造、学習方法に関して噛み砕いて説明してみました。
Chat-GPTはGPT-3というGPTの後継モデルをベースに開発されました。
GPTとGPT-3の違いは基本的にはモデルのサイズだけで、学習方法や大まかなモデル構造は共通しているため、GPTさえ理解すればGPT-3の理解にはほとんど手間取らないと思います
ニューラルネットをGPU向けに最適化するお仕事をしています
関連スライド





各ページのテキスト
GPT: Generative Pretrained Transformer 図だくさん解説 ~ Chat-GPTに至る道 ~
⾃⼰紹介 ROCMan • 来年春から新卒GPUエンジニアの修士2年生 • 深層学習とGPUプログラミングがちょっとわかる • たまに深層学習系の論文読んでスライドにまとめてます twitter垢: https://twitter.com/ROCmannn 2
前回のおさらい 前回のTransformer解説はこちら
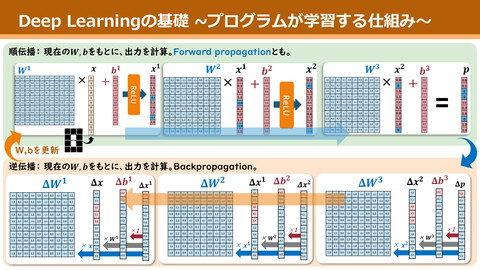
深層学習が何をやってるか 深層学習 …複雑な関数を、単純な線形変換()を大量に重ねて近似すること function(DNN) Rabbit Kawauso Cat 4
単純な線形変換() 𝑦 = 𝐴𝑐𝑡𝑖𝑣𝑎𝑡𝑒(𝑥𝑊 + 𝑏) (以降こいつをLinearって呼びます) Øこいつの重ね方に工夫が生まれる Ø𝑊, 𝑏の値をよしなに調整するのが学習 Activate Func 𝑥 * 𝑏 𝑊 𝑦 非線形性を生み、 表現力が向上 etc. 5
翻訳の主流︓Encoder-Decoderモデル Encoder Decoder I am a man . 私は人だ。 単語ベクトル群 単語ベクトル群 DNN DNN 文の意味っぽいベクトル 文の意味っぽいベクトル 6
Output Probabilities Transformer softmax Linear Layer Norm 並列性の高い計算フローを持つ Encoder-Decoder型DNN 本来は翻訳家 Nx だが、意味解釈能力が超凄い これ、何にでも応用できない? + Feed Forward Layer Norm Layer Norm + + Feed Forward Multi-Head Attention Layer Norm Layer Norm + + Multi-Head Attention Masked Multi-Head Attention 〜 + 〜 xN + Input Embedding Output Embedding Inputs Outputs 7
GPTを理解していこう︕ 8
⽬次 • GPT誕生の背景 • GPT • モデル構造 • Pre-train • Fine-tune 9
⽬次 • GPT誕生の背景 • GPT • モデル構造 • Pre-train • Fine-tune 10
GPT誕⽣の背景 Transformer凄い! NLPは全部Deepで行ける? LDLは学習コストが大きすぎる • 大量の解答付き学習データ • タスク毎に別々のモデルが必要 Ø全部できるやつ作れない? 分類AI ペットの話題 仕事の話題 類似判断AI 同じ主張 異なる主張
汎⽤モデルを作るためには︖ L真の意味での汎用モデルは困難 Øタスク毎に入出力の要求が異なるため • 分類:文章 -> 確率分布 • Q&A: 質問文 -> 回答文 入力文の意味解釈は共通して必要なはず 1. 入力文から意味ベクトルを作るモデルを学習(Pre-train) 2. あとはタスク毎に微調整して!(Fine-tune) 何かしら自然言語AI作りたい人は2だけやればok!
⽬次 • GPT誕生の背景 • GPT • モデル構造 • Pre-train • Fine-tune 13
Generative Pretrained Transformer “Improving Language Understanding by Generative Pretraining”(Aloc Radford et al. @OpenAI) Pre-train & Fine-tune方式の提唱 ØFine-tuneだけで多様なタスクに対応する汎用モデルを実現
⽬次 • GPT誕生の背景 • GPT • モデル構造 • Pre-train • Fine-tune 15
ひとまずモデル構造 Outputs ほぼTransformerのdecode部() Fine-tune Linear Pre-train • 前半の大部分のパラメタを学習、固定 Fine-tune • 最終層を連結、そこだけ追加学習 Pre-train Layer Norm + x12 Feed Forward Layer Norm + Masked Multi-Head Attention 〜 + Word Embedding Inputs 16
Output Probabilities 再掲)Transformer softmax Linear Layer Norm 並列性の高い計算フローを持つ Encoder-Decoder型DNN 本来は翻訳家 Nx だが、意味解釈能力が超凄い これ、何にでも応用できない? + Feed Forward Layer Norm Layer Norm + + Feed Forward Multi-Head Attention Layer Norm Layer Norm + + Multi-Head Attention Masked Multi-Head Attention 〜 + 〜 xN + Word Embedding Word Embedding Inputs Outputs 17
脇道)なんでdecoder部︖ softmax Linear Layer Norm encoderとdecoderは酷似 Ø本質的には大差無い masked-MHAかどうかの違い Nx Output Probabilities + Feed Forward Layer Norm Layer Norm + + Feed Forward Multi-Head Attention Layer Norm Layer Norm + + Multi-Head Attention Masked Multi-Head Attention 実はencoder使う派閥も有る ØそれがBERT 〜 + 〜 xN + Word Embedding Word Embedding Inputs Outputs 18
⽬次 • GPT誕生の背景 • GPT • モデル構造 • Pre-train • Fine-tune 19
Pre-trainで何を学習すべき︖ Outputs Fine-tune Pre-trainの目的 • モデル前半に文の意味解釈能力を! Linear Pre-train Layer Norm + x12 Feed Forward 何ができれば意味解釈してると言える? • 文章要約 • 文章についてのQ&A ØL学習データの作成が大変 Layer Norm + Masked Multi-Head Attention 〜 + Word Embedding Inputs 20
55% 飼う 次単語予測 不完全な文の次の単語を予測するよう学習 43% 撫でる 2% 食べる Output Probabilities softmax Linear Pre-train Layer Norm + J学習データの用意が簡単 x12 Feed Forward Ø適当な文章を拾って後半をmaskするだけ Layer Norm + Masked Multi-Head Attention Lこれで本当に文章理解できるのか? Ø結論:めちゃくちゃできた(後で詳しく) 〜 + Word Embedding Inputs START 私は 犬を □ EXTRACT 21
55% 飼う 学習時の⼊⼒⽂の⼯夫 吾輩は猫である。名前はまだない。 43% 撫でる 2% 食べる Output Probabilities softmax Linear Pre-train Layer Norm + x12 Feed Forward START 吾輩 は 猫 である 。 DELIM 名前 は まだ ない 。 EXTRACT Layer Norm + Masked Multi-Head Attention 入力文の節目に特殊なトークンを付与 〜 + Word Embedding 学習時はこれらの予測値は捨てる Inputs START 私は 犬を □ EXTRACT 22
⽬次 • GPT誕生の背景 • GPT • モデル構造 • Pre-train • Fine-tune 23
Fine-tune ①② ③④⑤ Linear etc. 1. 最後のLinear & softmaxを除去 2. 解きたいタスクの入力文を入れる ペットの話題 仕事の話題 趣味の話題 Pre-train Layer Norm + (適切な特殊トークンを入れる) • 分類:START 文 EXTRACT • 含意:START 文1 DELIM 文2 EXTRACT • Q&A: START Q DELIM A EXTRACT x12 Feed Forward Layer Norm + Masked Multi-Head Attention 3. EXTRACTに対応するベクトルを取得 4. それに新規のLinear層()を接続 5. そのLinear層だけちょっと学習 〜 + Word Embedding Inputs START ① 私は ② 犬を ③ 飼う ④ EXTRACT ⑤ 24 85% 1% 14%
GPTの性能 様々なタスクで最高性能発揮 • 文章のジャンル分類 • 2文間の論理関係判断 • 2文間の類似性判断 • Q&A
GPTまとめ 多様な自然言語タスクを解ける汎用モデルの需要 Ø文章解釈力を持つ基盤モデルを作り、タスク毎に微調整しよう Pre-train • 次単語予測の大量学習でモデルに解釈力を! Fine-tune • モデルの最終層だけ取り替え、そこだけ追加学習
読了感謝︕ twitter垢: https://twitter.com/ROCmannn ↑少しでもわかりやすいと思ってくれたらフォローお願いします! 27